Vision
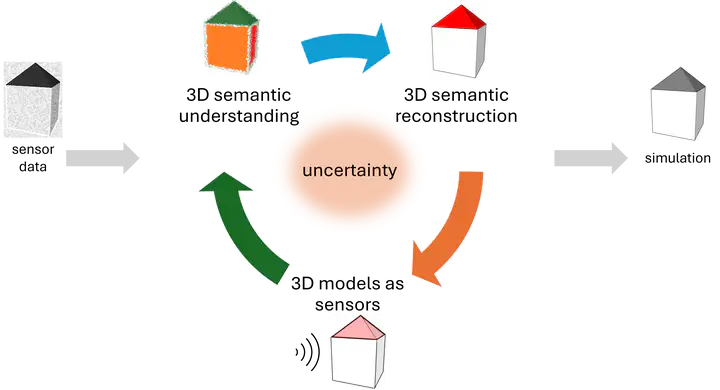
CV4DT aims to gather researchers willing to push forward the boundaries of machine learning, photogrammetry, and computer vision. As shown above, our CV4DT research agenda focuses on the following aspects:
- 3D semantic understanding,
- 3D semantic reconstruction,
- 3D models as sensors,
- Uncertainty quantification – overarching all three aspects.
The rationale is that those aspects are interdependent and indispensable in creating digital twins from any sensory data, enabling any digital simulations before real-world action occurs.
We understand digital twin not as a mere 3D geometric representation of reality, but rather as a 3D model comprising a) 3D minimum-viable and watertight geometric representation, b) hierarchical semantics, c) estimated uncertainty of both predicted semantics and geometry; enabling updates of digital twins in the presence of new evidence.
The ultimate goal is to create methods enabling robust digital twinning, delivering impact to society in real-time monitoring and simulation of physical systems, leading to more efficient decision-making and reduced operational costs. They also shall support sustainable development by optimising resource use and minimising environmental impact across industries.
Beyond science itself, we aim to create an environment where researchers of any background will thrive and develop their skills and careers. But first and foremost… have fun pursuing their passion!